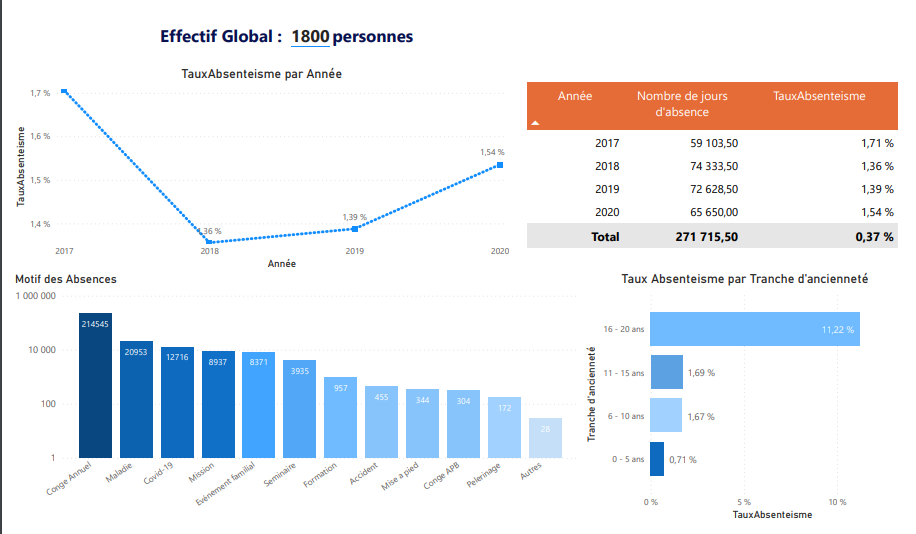
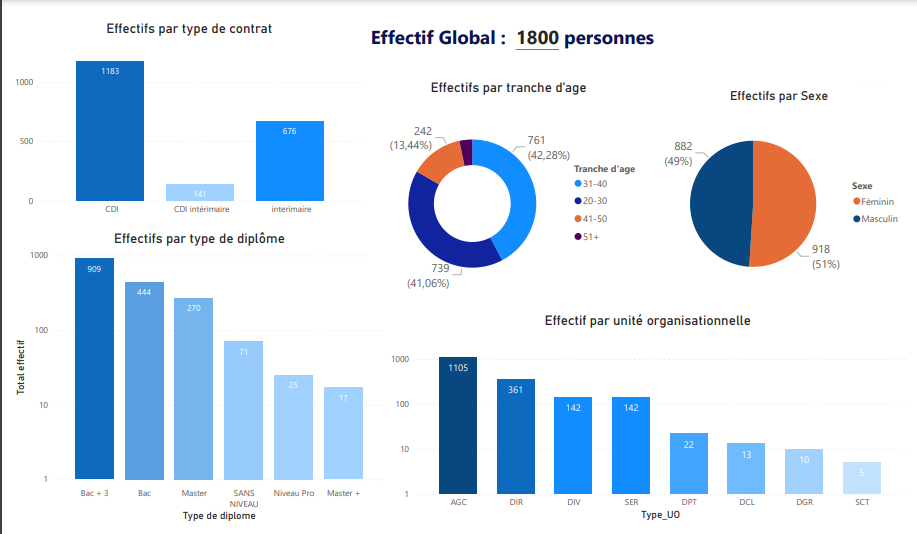
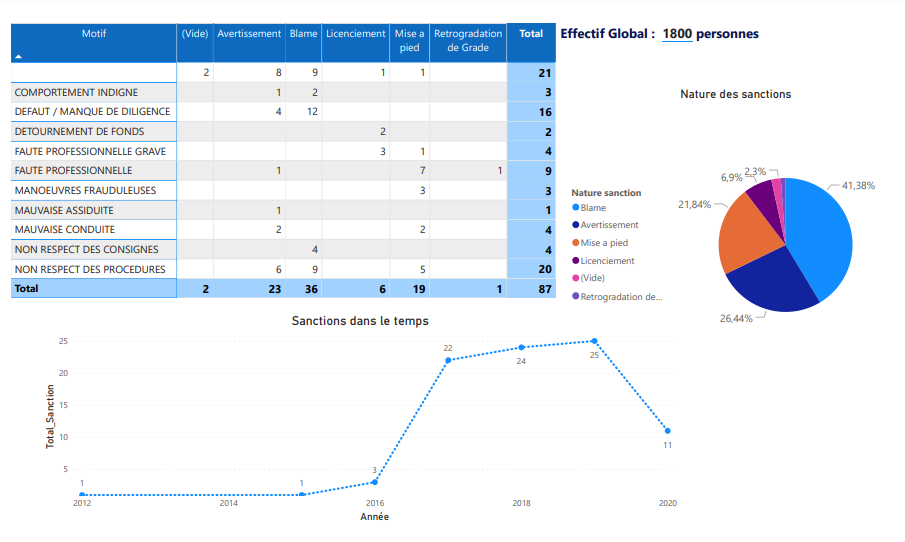
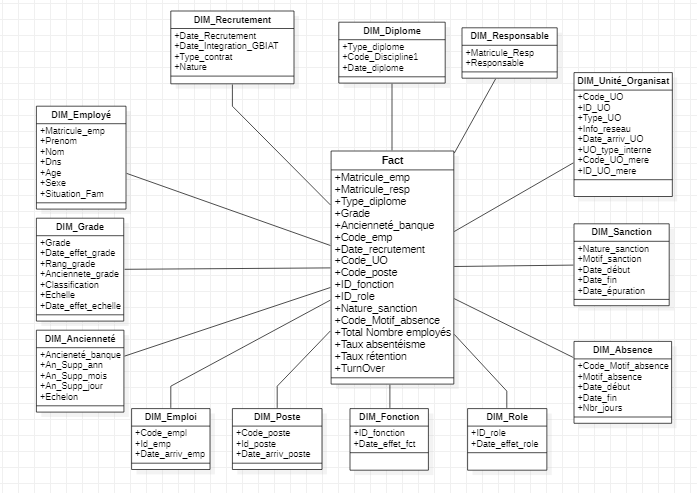
ELT is a process of gathering information from any number of sources, loading it into a location for processing, and then transforming it into actionable decision data.
Extraction - The first step, works the same way in both approaches to data management. Raw data streams from a virtual infrastructure, software and applications are ingested entirely or according to predefined rules.
Loading - This is where the ELT branch separates itself from its ETL cousin. Rather than providing so much raw data and loading it onto a temporary processing server before transformation, ELT delivers all the data to the site where it will then reside. This reduces the cycle between retrieval and delivery, but requires much more work before the data becomes useful.
Transformation - The database or warehouse sorts and normalizes the data, retaining only some or all of it so that it is accessible for custom reporting purposes. The storage load for such a large amount of data is greater, but it provides more opportunities for personalized exploration for relevant business intelligence data in near real time.
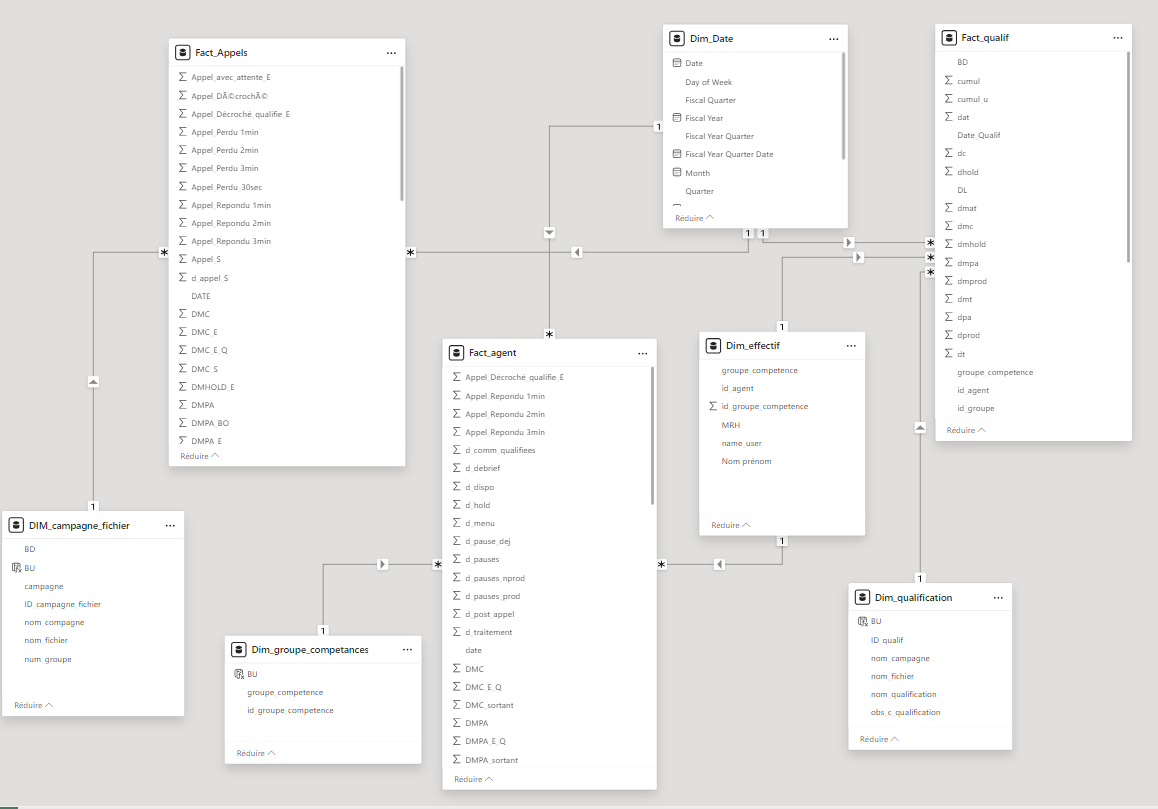
It is important to know that just as an OLTP system is based on an RDBMS, an OLAP BI system is based on the data warehouse. The data warehouse is the essential basis for obtaining the answers to the questions that are essential for decision making and for steering the company.
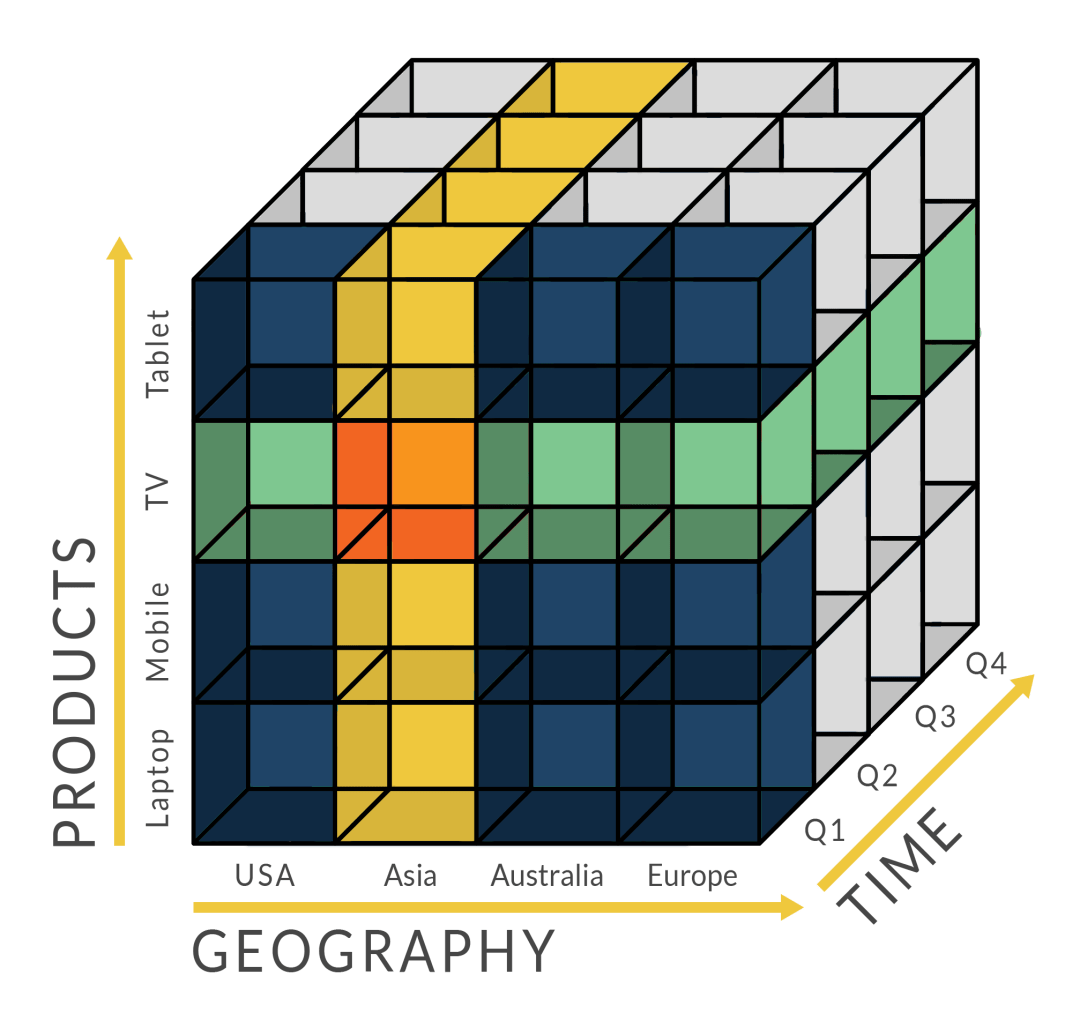
If you pay attention, you will realize that conceptually, a data warehouse is a multidimensional model. It is a denormalized relational model, and moving from an operational database model to a business intelligence database model means transforming the elements of the operational database model into "dimensions" and "facts".
This transformation is necessary because, as mentioned above, the OLTP model only provides a flattened and static view of the data in a point of time space. This flattened and static view, which we call a database, is necessary to ensure the performance of operational transactions, and thus to guarantee the 24-hour availability and the high performance of the DBMS.
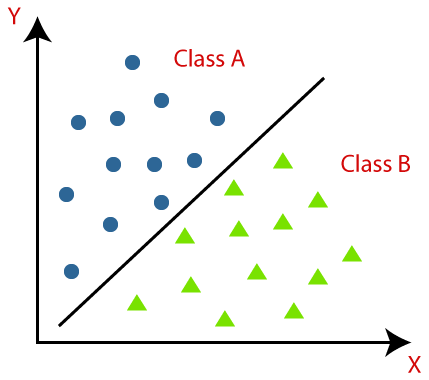
Classification is a type of machine learning problem which aims to predict a class label for a given input data point. It is one of the most widely used techniques in machine learning and is applied in various domains like image classification, spam detection, sentiment analysis and many more.
There are two main types of classification problems: binary
classification and multi-class classification. In binary classification, the goal is to predict one of two possible class labels, such as yes or no, true or false, or spam or not spam.
Multiclass classification involves predicting more than two possible class labels.Machine learning algorithms used for classification fall into two broad categories: linear and nonlinear. Linear algorithms, such as logistic regression, linear discriminant analysis and support vector machines, work by drawing a straight line or plane that separates the different classes.
The performance of a classification algorithm is typically measured by metrics such as :
Accuracy measures the percentage of correctly predicted class labels, while precision measures the percentage of true positives among all positive predictions. Recall measures the percentage of true positives among all actual positive instances, and F1 score is the harmonic mean of precision and recall.
1 - Multidimensional conceptual view
2 - Transparency
3 - Accessibility.
4 - Single reporting service
5 - Client-server architecture
6 - Generic dimensionality
7 - Automatic adaptation of the physical level
8 - Multi-user support
9 - Unrestricted cross-dimensional operations.
10 - Intuitive data manipulation.
11 - Flexible reporting.
12 - Unlimited dimensions & levels of aggregation.
2020 - 2021
2022 - 2024
Juin 2021 - Today

Tunis - Tunisia - +216 29 566 857
More likely to respond within :
Mon – Fri: 9:00 am – 7:00 pm,
Sat – Sun: 10:00 am – 5 pm
This site was created with the Nicepage